个人认为Spark SQL应该是Spark BDAS各个组件中最简单的了,在Spark 2.0中,Spark SQL变得更加简单了。本文不再介绍概念性的内容,仅仅通过一个示例来熟悉Spark 2.0中的Spark SQL。本文使用的数据下载自 DATA.GOV.UK,点击即可下载。
创建 SparkSession
这一步是Spark 2.0与之前版本的主要区别之一,2.0时代我们不再需要一步一个脚印地去创建SparkConf, SparkContext, SQLContext/HiveContext等等,只需要一个SparkSession就齐活了。在spark-shell中,Spark会为我们自动创建一个名为spark的SparkSession对象,这里我们与之保持一致:
1 | val spark = SparkSession.builder().appName("Spark-2.0-SQL-APP-1").master("local") |
这里首先指定了appName以及master运行方式,然后添加了一些配置选项,还启用了Hive支持(后面要把数据持久化到Hive仓库中)。两个import语句对于新手可能有点别扭,这里简单提一句,后面的toDF()方法和“$”操作符,需要第一个import的隐式转换。第二个import更容易理解一些,引入spark.sql之后,后面在需要调用spark.sql()方法来执行SQL语句的时候,直接使用sql()即可。注意这里的spark不是包名,而是我们刚刚创建的名为spark的SparkSession对象。
定义 case class
根据数据格式定义一个case class,用于对数据进行模式匹配。在Scala 2.10版本之前,case class中的字段不能超过22个。不过从目前最新的Scala 2.11版本开始,已经没有这个限制了。
1 | case class Energy(Name: String, Postcode: String, Date: String, Unit: String, MeterReading: Int, Output: Int, CapacityKW: Double) |
获取 DataFrame
DataFrame是Spark SQL中非常重要的一个抽象,在概念上大致等同于关系数据库中的表。在Scala API中,DataFrame是Dataset[Row]的别名。
1 | val columns = "Name,Postcode,Date,Unit,Meter Reading,Output,Installed Capacity KW" |
这里我们从SparkSession对象中获取SparkContext对象,用来读取CSV文件,然后过滤掉表头,对每行数据进行“,”拆分,然后映射为case class对象,这些操作都是Spark中最普通的RDD操作,最后我们调用toDF()方法把RDD转为DataFrame。
操作 DataFrame
1 | df.printSchema() |

1 | val jsonData = df.toJSON |
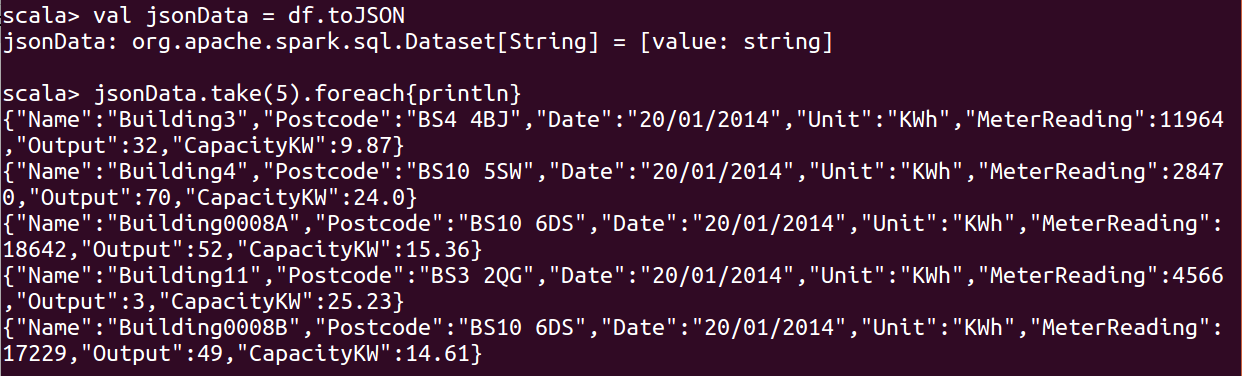
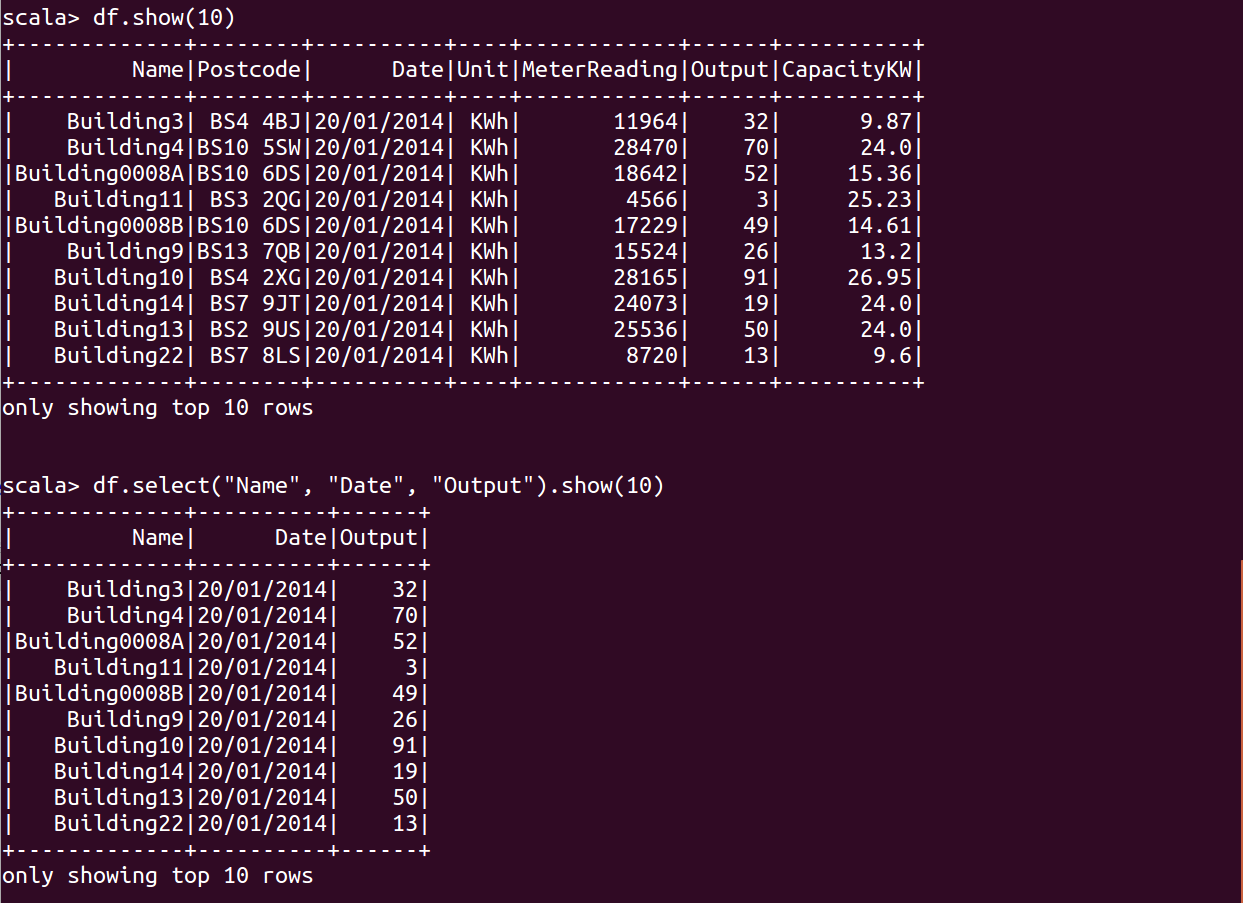
1 | df.show(10) |
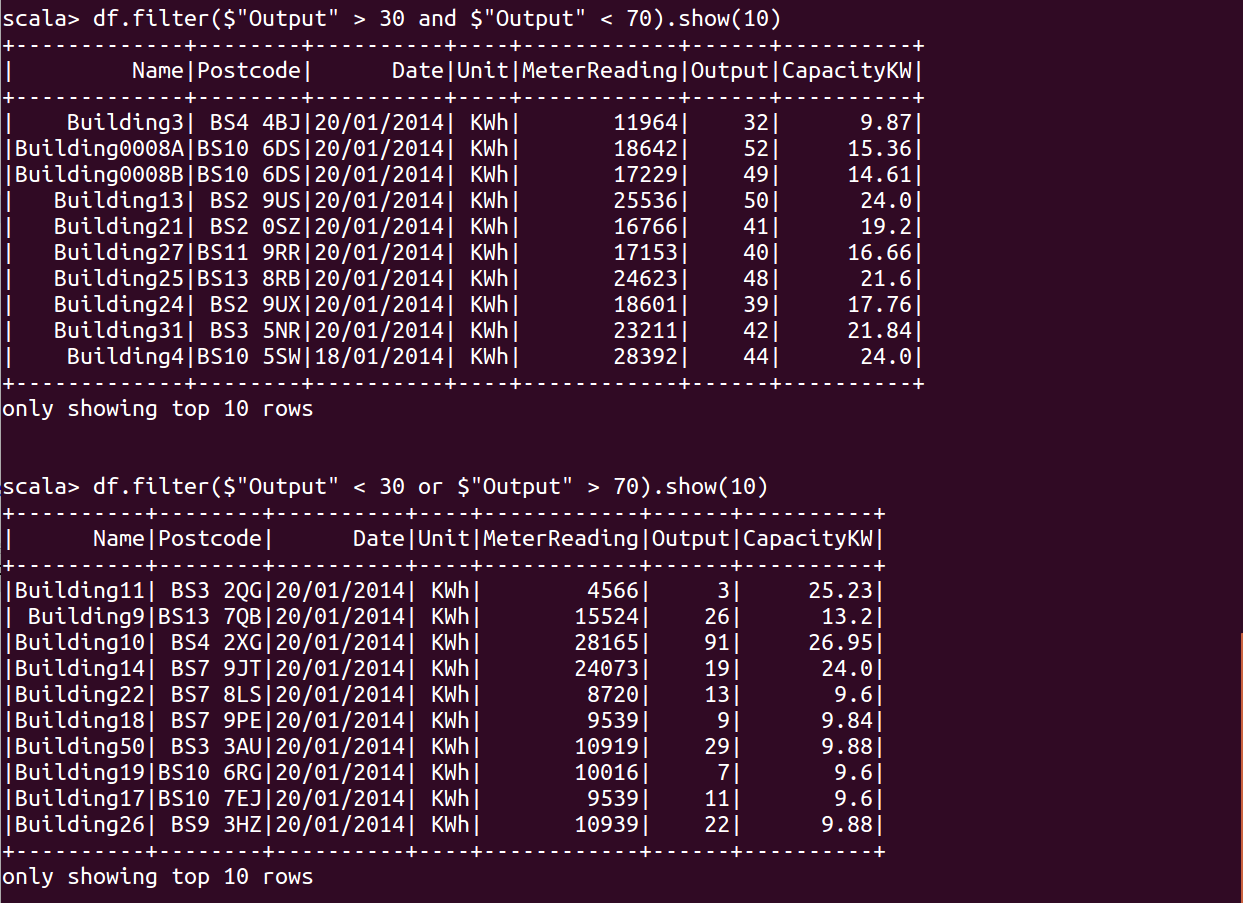
1 | df.filter($"Output" > 30 and $"Output" < 70).show() |
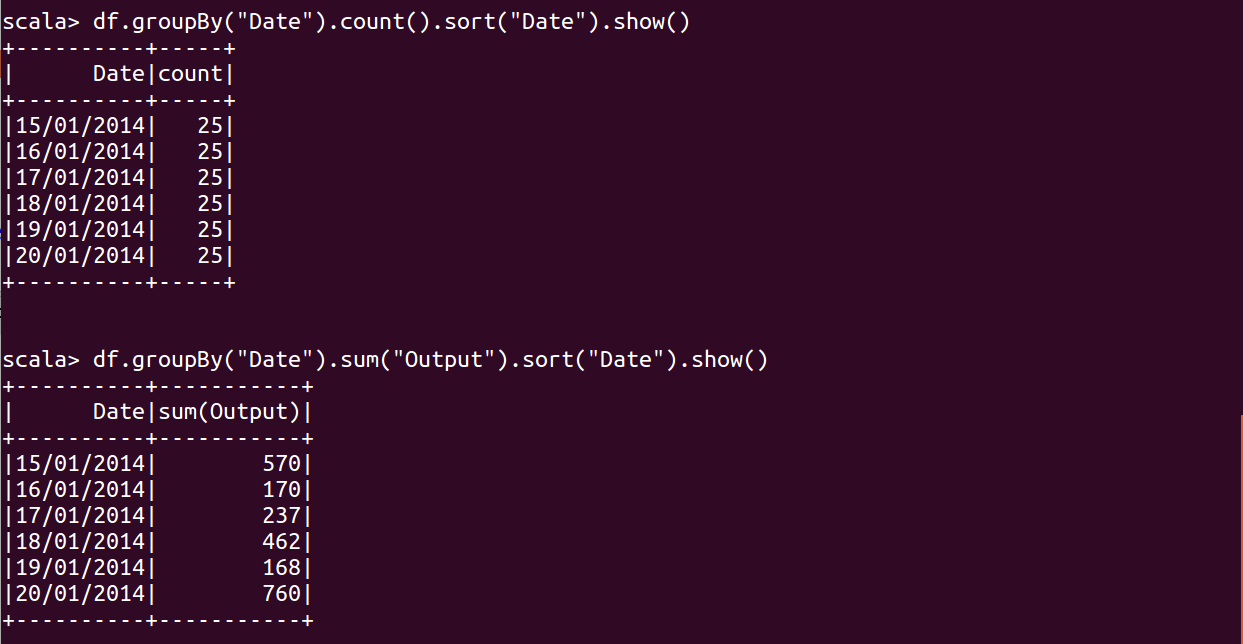
1 | df.groupBy("Name").count().show() |
使用 SQL
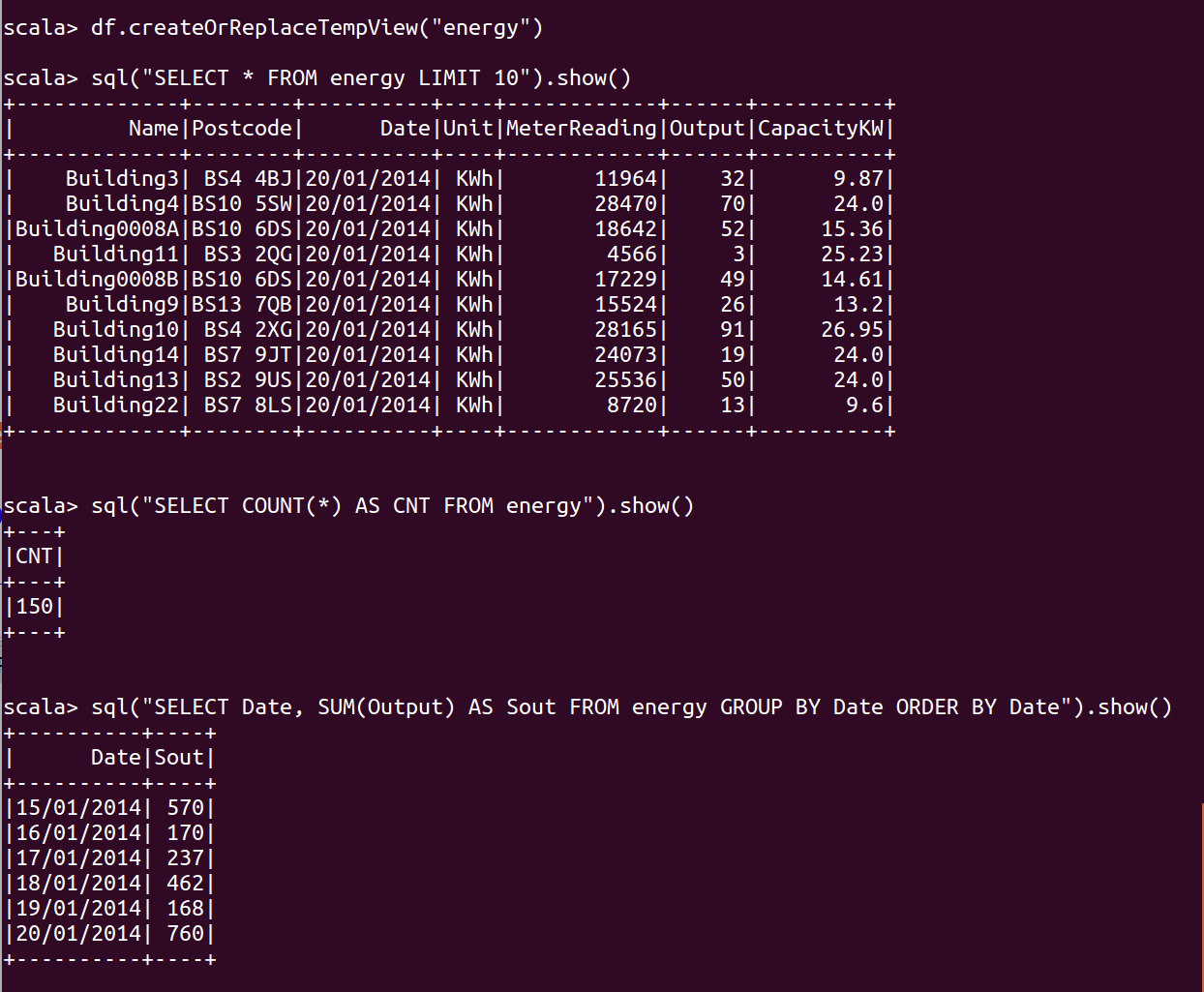
1 | df.createOrReplaceTempView("energy") |
使用 UDF
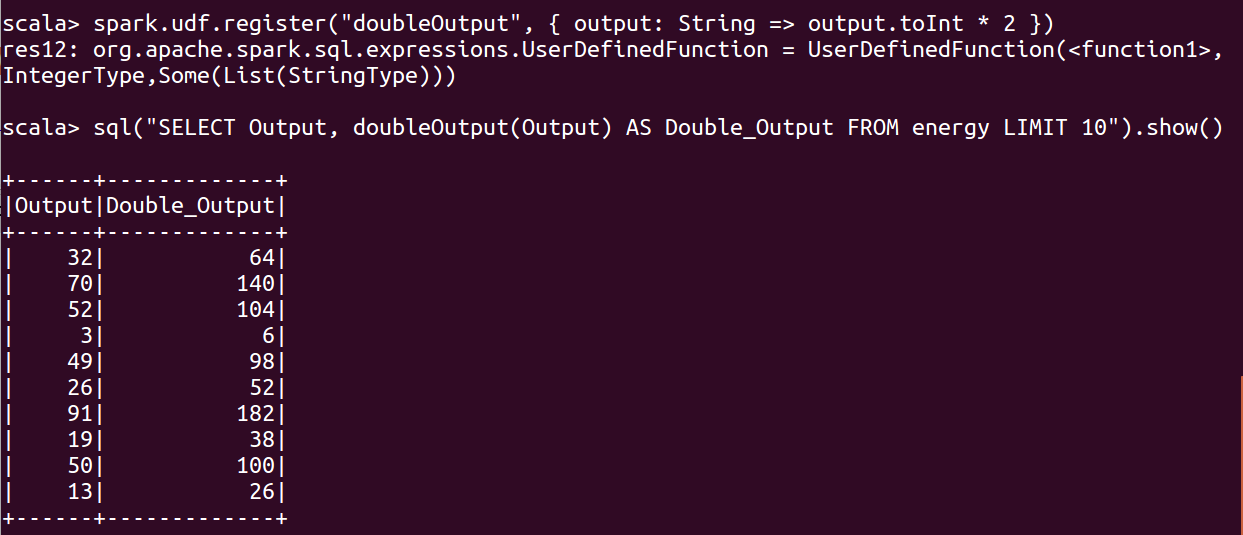
1 | spark.udf.register("doubleOutput", { output: String => output.toInt * 2 }) |
持久化表
1 | df.write.mode(SaveMode.Overwrite).saveAsTable("hive_energy") |
完整代码
Scala 部分:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55package com.qinm.tools.spark.sql
import scala.reflect.runtime.universe
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.SaveMode
object sparksql1 extends App {
val spark = SparkSession.builder().appName("Spark-2.0-SQL-APP-1").master("local")
.config("spark.some.config.option", "some-value")
.enableHiveSupport()
.getOrCreate()
import spark.implicits._
import spark.sql
case class Energy(Name: String, Postcode: String, Date: String, Unit: String, MeterReading: Int, Output: Int, CapacityKW: Double)
val columns = "Name,Postcode,Date,Unit,Meter Reading,Output,Installed Capacity KW"
val df = spark.sparkContext.textFile("input/energy_generation_wc_140114.csv")
.filter { !_.contains(columns) }
.map { _.split(",") }
.map { p => Energy(p(0), p(1), p(2), p(3), p(4).trim().toInt, p(5).trim().toInt, p(6).trim().toDouble) }
.toDF()
df.show(10)
df.printSchema()
val jsonData = df.toJSON
jsonData.take(5).foreach { println }
df.select("Name", "Date", "Output").show()
df.filter($"Output" > 30 and $"Output" < 70).show()
df.filter($"Output" < 30 or $"Output" > 70).show()
df.groupBy("Name").count().show()
df.groupBy("Date").count().sort("Date").show()
df.groupBy("Date").sum("Output").sort("Date").show()
df.createOrReplaceTempView("energy")
sql("SELECT * FROM energy LIMIT 10").show()
sql("SELECT COUNT(*) AS CNT FROM energy").show()
sql("SELECT Date, SUM(Output) AS Output_Sum FROM energy GROUP BY Date ORDER BY Date").show()
spark.udf.register("doubleOutput", { output: String => output.toInt * 2 })
sql("SELECT Output, doubleOutput(Output) AS Double_Output FROM energy LIMIT 10").show()
df.write.mode(SaveMode.Overwrite).saveAsTable("hive_energy")
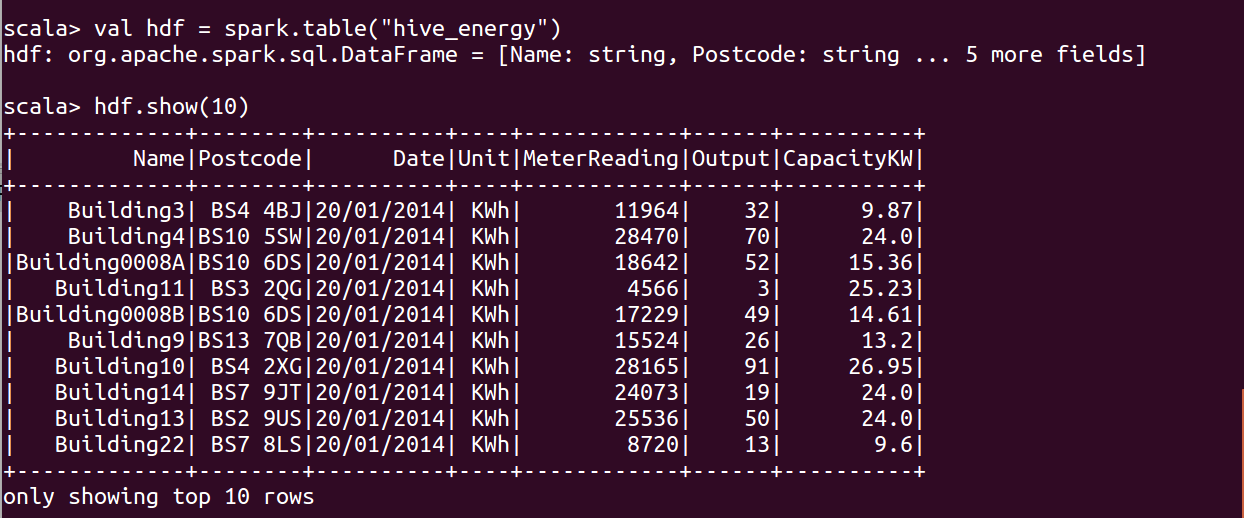
val hdf = spark.table("hive_energy")
hdf.show(10)
}
Maven pom 部分:
1 | <dependency> |