分类
每个人每天都会进行很多次的分类操作。比如,当你看到一个陌生人,你的大脑中的分类器就会根据TA的体貌特征、衣着举止,判断出TA是男是女,是穷是富等等。这就是分类操作。
其中,男人、女人、穷人、富人,这些是类别;那个陌生人,是个待分类项;把一个待分类项映射到一个类别的映射规则,就是一个分类器。
分类算法的任务就是构造出分类器。
本文翻译自O’Reilly出版Tom White所著《Hadoop: The Definitive Guide》第4版第19章,向作者致敬。该书英文第4版已于2015年4月出版,至今已近15个月,而市面上中文第3版还在大行其道。Spark一章是第4版新增的内容,笔者在学习过程中顺便翻译记录。由于笔者也在学习,难免翻译不妥或出错,欢迎方家斧正。翻译纯属兴趣,不做商业用途。
个人认为Spark SQL应该是Spark BDAS各个组件中最简单的了,在Spark 2.0中,Spark SQL变得更加简单了。本文不再介绍概念性的内容,仅仅通过一个示例来熟悉Spark 2.0中的Spark SQL。本文使用的数据下载自 DATA.GOV.UK,点击即可下载。
这一步是Spark 2.0与之前版本的主要区别之一,2.0时代我们不再需要一步一个脚印地去创建SparkConf, SparkContext, SQLContext/HiveContext等等,只需要一个SparkSession就齐活了。在spark-shell中,Spark会为我们自动创建一个名为spark的SparkSession对象,这里我们与之保持一致:
1 | val spark = SparkSession.builder().appName("Spark-2.0-SQL-APP-1").master("local") |
这里首先指定了appName以及master运行方式,然后添加了一些配置选项,还启用了Hive支持(后面要把数据持久化到Hive仓库中)。两个import语句对于新手可能有点别扭,这里简单提一句,后面的toDF()方法和“$”操作符,需要第一个import的隐式转换。第二个import更容易理解一些,引入spark.sql之后,后面在需要调用spark.sql()方法来执行SQL语句的时候,直接使用sql()即可。注意这里的spark不是包名,而是我们刚刚创建的名为spark的SparkSession对象。
今天是七夕,看到一则关于“京东”名字来源的八卦,什么东哥的前女友、奶茶妹妹一个排的前男友balabala的,忽然想到能不能用算法对那一个排的前男友聚聚类,看看奶茶妹妹的喜好啊品味啊什么的,然后再看看东哥属于哪一类,一定很有(e)趣(su)。可惜手头没有那一排人的资料,只好作罢。由此看来聚类算法还挺有价值的,比如研究下非诚勿扰、世纪佳缘之类的……
言归正传,所谓聚类问题,就是给定一个元素集合D,其中每个元素具有n个可观察属性,使用某种算法将D划分成k个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高。其中每个子集叫做一个簇(cluster)。
上面这段话翻译为人类语言是这样的:有一堆人,每个人的胸牌上都写着“性别:男/女;年龄:XX”,我们可以根据性别把这堆人分为男、女两个子集,或者根据年龄把他们分为老、中、青、少四个子集。
乍一看,这不还是在做分类操作吗?聚类(clustering)与分类(classification)的不同之处在于:分类是一种示例式的有监督学习算法,它要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应,很多时候这个条件是不成立的,尤其是面对海量数据的时候;而聚类是一种观察式的无监督学习算法,在聚类之前可以不知道类别甚至不给定类别数量,由算法通过对样本数据的特征进行观察,然后进行相似度或相异度的分析,从而达到“物以类聚”的目的。
K-Means算法是最简单的一种聚类算法。
我们来看一下当我们运行一个Spark作业时,会发生什么。在最高级别上,有两个独立的实体:驱动(driver)和执行器(executors)。驱动持有(hosts)应用(SparkContext),调度作业中的任务。执行器独立于应用,在应用的持续时间内运行,执行应用的任务。通常情况下,驱动作为客户端运行,不受集群管理器的管理,而执行器运行在集群中的多台机器上,但并非总是如此。在本节的其余部分,我们假定应用的执行器已经在运行。
图19-1说明了Spark是怎样运行一个作业的。当在一个RDD上执行一个行动时(比如count()),会自动提交一个Spark作业。内部来看,这会导致SparkContext的runJob()方法被调用(图19-1步骤1),该方法将调用传递给调度器,调度器作为驱动的一部分运行(步骤2)。调度器由两部分组成:DAG调度器和任务调度器。DAG调度器会把作业拆解为多个阶段组成的DAG。任务调度器的责任是把每个阶段的任务提交到集群。
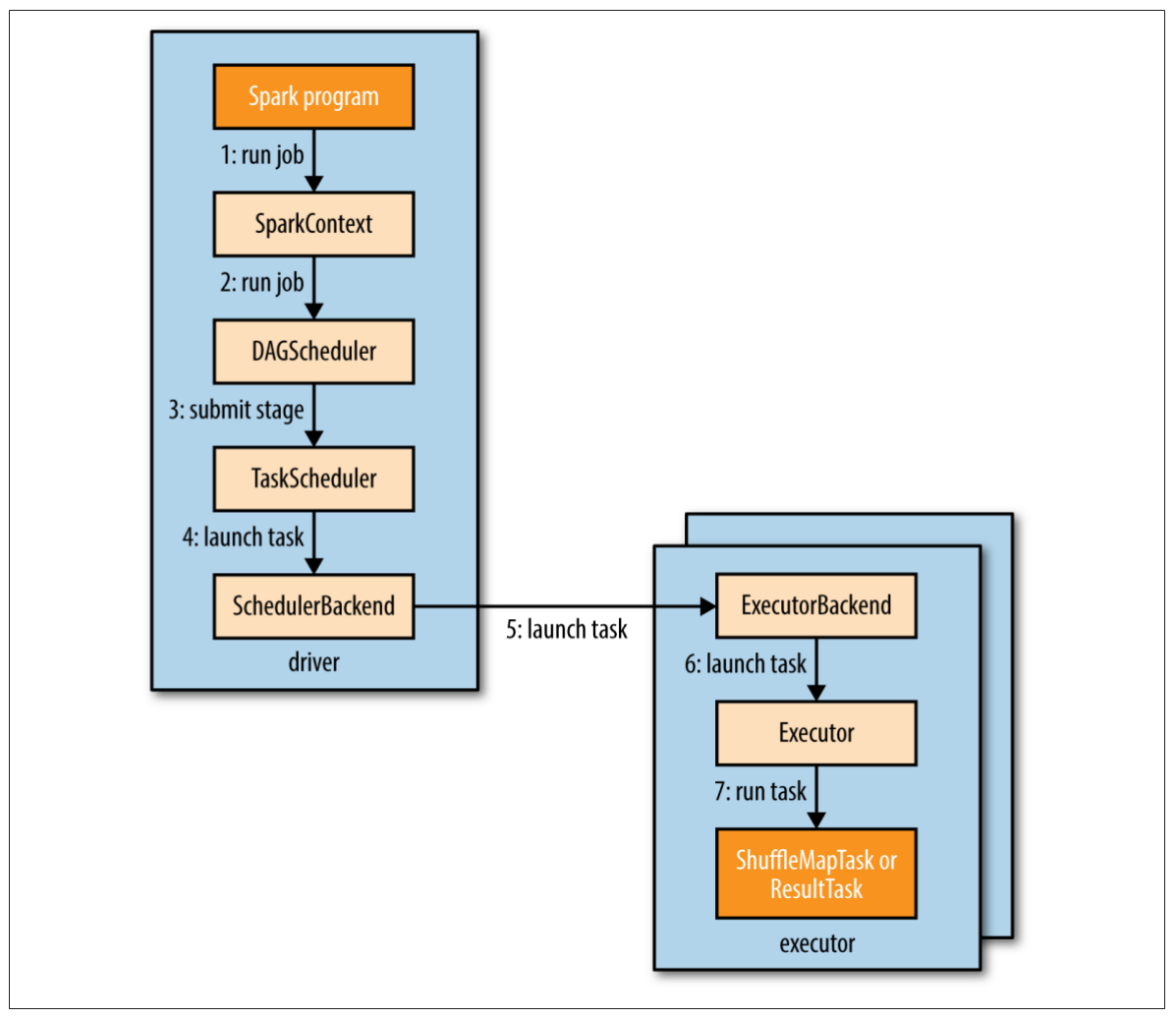
图19-1. Spark怎样运行一个作业
接下来,我们来看看DAG调度器是怎样构建一个DAG的。
回到本章开头的例子,我们可以把“年度-气温”的中间数据集缓存在内存中:
1 | scala> tuples.cache() |
调用cache()不会立刻把RDD缓存到内存中,只是对这个RDD做一个标记,当Spark作业运行的时候,实际的缓存行为才会发生。因此我们首先强制运行一个作业:
1 | scala> tuples.reduceByKey((a, b) => Math.max(a, b)).foreach(println(_)) |
关于BlockManagerInfo的日志显示,作为作业运行的一部分,RDD的分区会被保持在内存中。日志显示这个RDD的编号是4(在调用cache()方法之后的控制台输出中,也能看到这个信息),它包含两个分区,标签分别是0和1。如果在这个缓存的数据集上运行另一个作业,我们会看到这个RDD将从内存中加载。这次我们计算最低气温:
1 | scala> tuples.reduceByKey((a, b) => Math.min(a, b)).foreach(println(_)) |
RDD是每个spark程序的核心,本节我们来看看更多细节。
创建RDD有三种方式:从一个内存中的对象集合,被称为并行化(parallelizing) 一个集合;使用一个外部存储(比如HDFS)的数据集;转换已存在的RDD。在对少量的输入数据并行地进行CPU密集型运算时,第一种方式非常有用。例如,下面执行从1到10的独立运算:
1 | val params = sc.parallelize(1 to 10) |
函数performExpensiveComputation并行处理输入数据。并行性的级别由属性spark.default.parallelism决定,该属性的默认值取决于Spark的运行方式。本地运行时,是本地机器的核心数量,集群运行时,是集群中所有执行器(executor)节点的核心总数量。
可以为某个特定运算设置并行性级别,指定parallelize()方法的第二个参数即可:
1 | sc.parallelize(1 to 10, 10) |
在Spark shell中运行了一个小程序之后,你可能想要把它打包成自包含应用,这样就可以多次运行了。
示例19-1. 使用Spark找出最高气温的Scala应用
1 | import org.apache.spark.SparkContext._ |